
Faster Experimentation Yields Better Models
In order to build the best performing models, we often need to run a lot of experiments. The faster we can run experiments, the more effective we can make your models. Machine Learning models often have many parameters that can have small, but noticeable impacts on effectiveness. Deep Learning model effectiveness can vary significantly depending on how the neural networks are structured. Parameters governing the input to models, such as the number of characters or words to represent text, or different frequency band slices of audio, can also effect model output.

Traditionally, these are some of the areas data scientists spend an incredible amount of time fine tuning. In order for us to build models as fast as we do that perform as well as ours do, we've built the Mayetrix Experimenter platform. The Mayetrix Experimenter allows us to easily define hundreds or thousands of experiments, and then execute them in parallel on many machines. Once the experiment results return with the most effective model configurations, we're able to use them to train and deploy the best models.
More Experimenters Means More Experiments
One of the challenges with data science, is that only a few data scientists are really strong at software development and machine learning. Most data scientists, are, however, comfortable building and evaluating models in simple, dependency light, local environments using snapshots of ground truth data, using their own familiar tools. Mayetrix Experimenter tries to make it easy to get more data scientists with little or no background in the problem at hand to grab a simple local experiment kit and try to outperform the baseline experiment. The figure and sequence of events below describes how we address this challenge.
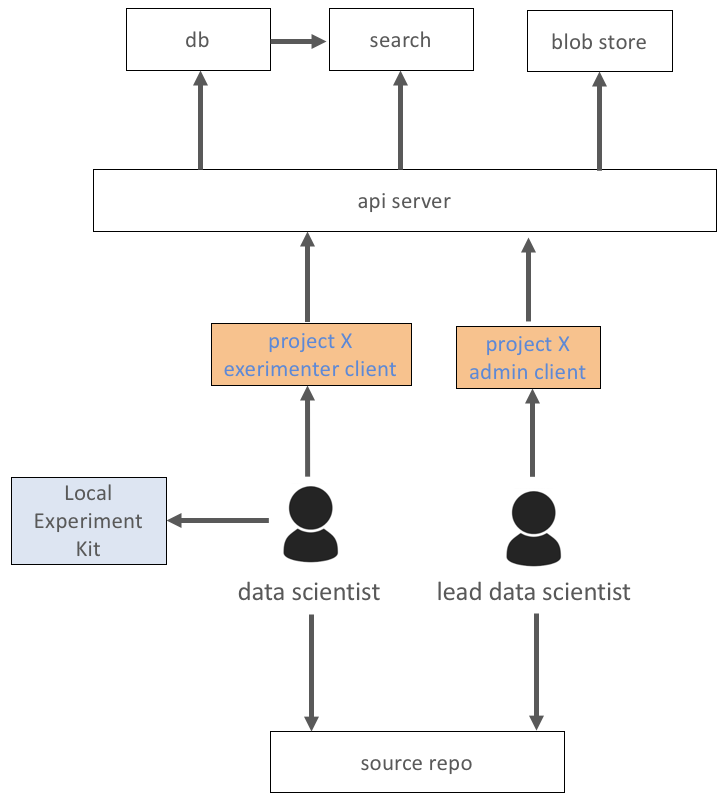
1. Lead Data Scientist snapshots the ground truth, implements a baseline including efficacy assessment technique. Results are stored in Mayetrix DB and the source repo following agreed upon convention.
2. Data Scientists with no system knowledge and minimal development skills downloads prepared kits which may include large files like video, audio, etc. Data Scientist is now ready for easy experimentation with minimal dependencies using their own environment.
3. Data Scientist kit includes agreed upon runtime model execution API. Lead data scientist reviews, and easily integrates into production line.