

This work was done in collaboration with the amazing folks at Pictory.AI.
Perhaps exemplified by the stunning rise of generative AI and ChatGPT, Large Language Models (LLMs) have become increasingly popular in recent years due in large part to their ability to read and generate complex language and complete a wide range of tasks. However, with increasing use of these models, it has become increasingly important to quantify the efficacy of LLM completions and ensure their accuracy and trustworthiness. While standard metrics can be used to judge how well these models are doing in established areas like language conversion, there is now a massive interest in leveraging generative algorithms to solve a variety of complex tasks which have no standard metrics.
Our work on quantifying efficacy for abstractive summarization is just one example of this trend; our approach can be applied to a wide array of generative tasks like automated reviews, question answering, chatbot responses and more. To achieve our goal of developing a measurably accurate abstractive summarization model, we need to carefully consider the role of training data and parameter optimization. One key aspect is the availability of training data that is both relevant and diverse. We need a large corpus, around a minimum of 300 examples, that covers a wide range of topics and styles, so that our model can learn to summarize various types of information. In addition, we need to ensure that we optimize the model parameters to achieve the best possible performance.
xyonix solutions
Learn more about Xyonix's Virtual Concierge Solution, the best way to enhance customer satisfaction for industries like hospitality, retail, manufacturing, and more.
By systematically exploring different training data and parameter settings, we developed a robust and flexible framework that can be applied to a wide range of summarization tasks.
However, assessing the efficacy of content generation models for complex tasks, such as summarization, without a standard metric remains a challenge.
Our Models
To evaluate the efficacy of LLMs, human annotators and machine-generated outputs are compared using various embedding approaches. We first generate automated summaries of our test corpus. Next, we compare these summaries with human-generated summaries of the same texts. We supplement our in-house annotated corpus with texts from the CNN /Daily Mail dataset where authors provided single-sentence summaries of their articles; we then entered this annotated corpus of text (both long and summarized form) into an AI21 powered few-shot learner LLM. This model is designed to quickly learn from a small set of examples and generalize to new tasks. Our models are specifically trained on the CNN News data, where we formed a prompt with a few example articles and corresponding summaries. The base model we used in the experiment was a 17 billion parameter LLM AI21 calls the j1-grande. The experiment used a total of five different models, each with its own set of parameters as seen in the image below. The parameters varied in the following ways:
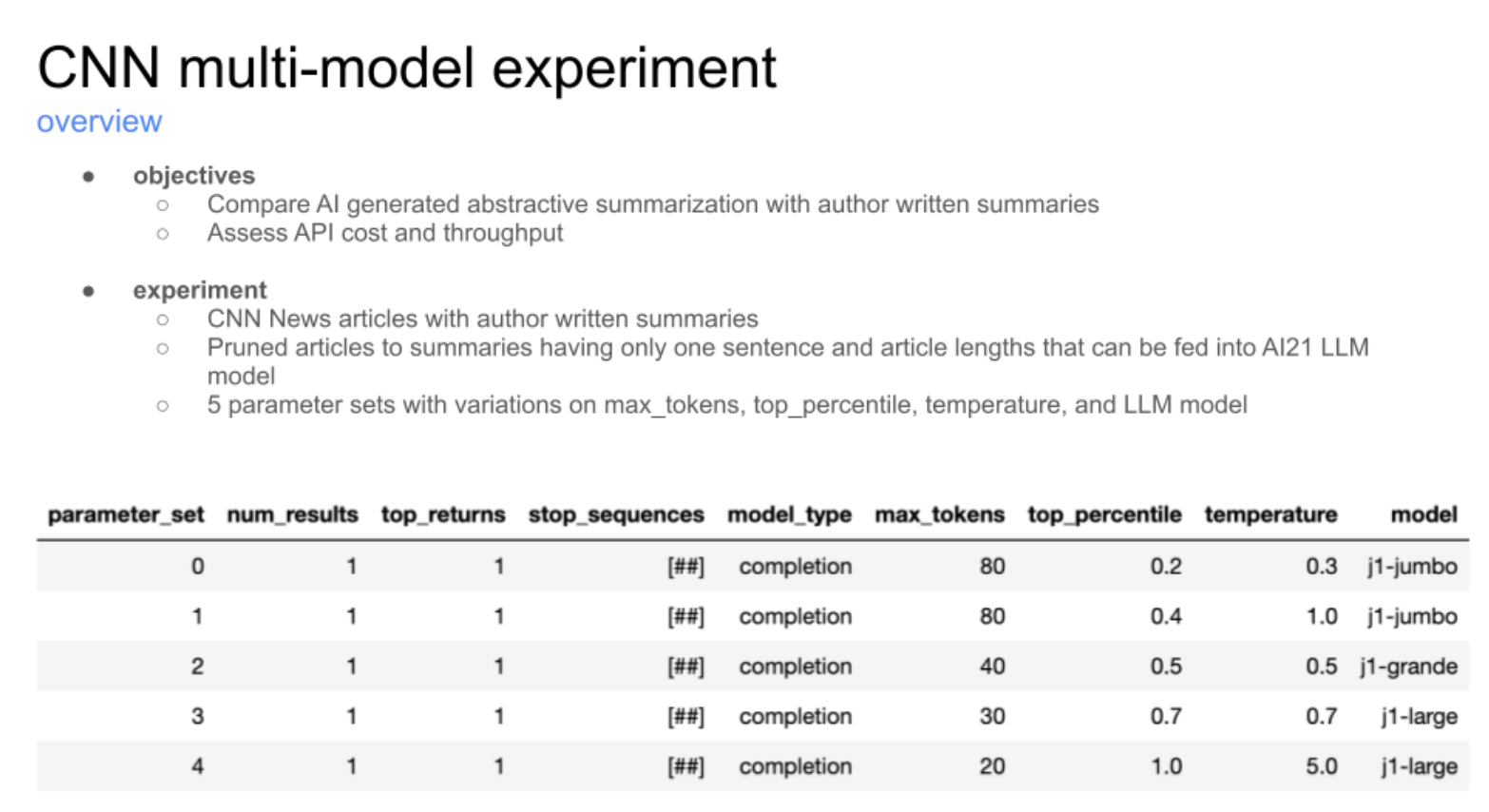
Tokens
In AI language models, tokens refer to individual words or symbols that are used to represent input text. The max_tokens parameter in the AI21 model controls the maximum number of tokens that can be generated for a given text completion. This is an important parameter as it affects the length and quality of the generated text. The J1 models, for example, have a capacity of 2048 tokens in total, including both the prompt and the generated completion, which corresponds to an average of 2300-2500 English words. By setting an appropriate value for max_tokens, we can control the length and complexity of the generated text and ensure that it is suitable for the intended task.
Percentile
The top_percentile parameter in the AI21 model controls the percentile of probability from which tokens are sampled during text completion. A value lower than 1.0 means that only the corresponding top percentile of options is considered, and less likely options will not be generated. This results in more stable and repetitive completions, which can be useful for certain applications where consistency and accuracy are important. For example, a value of 0.9 will only consider tokens comprising the top 90% probability mass. By setting an appropriate value for top_percentile, we can control the quality and reliability of the generated text.
Temperature
The temperature parameter in the AI21 model controls the sampling randomness during text completion. Increasing the temperature tends to result in more varied and creative completions, whereas decreasing it results in more stable and repetitive completions. A temperature of zero effectively disables random sampling and makes the completions deterministic. Setting temperature to 1.0 samples directly from the model distribution. Lower (higher) values increase the chance of sampling higher (lower) probability tokens. A value of 0 essentially disables sampling and results in greedy decoding, where the most likely token is chosen at every step. By setting an appropriate value for temperature, we control the creativity and variability of the generated text, and ensure that it is suitable for the intended task.
Choosing Metrics of Comparison
Once our models have generated summaries, we need a method to compare these summaries to human generated summaries. Typically, there are two main methods to go about solving this problem.
The first is through string based comparison, the computer, for example, may analyze characters of both strings to determine to what extent they are the same. If the characters in each string match exactly, the strings are identical. However, if the strings differ by even a single character, they are considered different, e.g. car and cat. The idea is that the closer the words are literally, the closer they would be in meaning, eg. car and cab. Once we have the two strings, we can use an algorithm to calculate the edit or Levenshtein distance between them. The edit distance is the minimum number of single-character edits required to transform one string into the other. A lower edit distance indicates a higher similarity between the two strings.
Embeddings are another, more sophisticated and modern technique commonly used for comparing text similarity. Instead of relying on the actual characters or words in the text,
embeddings map words or phrases to a high-dimensional space, where the distance between them reflects their semantic similarity; this means that even if two pieces of text contain different words, their embeddings may still be similar if the underlying meaning is similar.
In our case, we are using sentence embeddings to compare the similarity between sentences in our text data. This approach allows us to identify more complex similarities between sentences, such as recognizing related concepts or ideas that may not be immediately apparent from a string-based comparison.
To use embeddings for comparing human-generated and machine-generated summaries, we first need to create embeddings for each summary. This can be done using pre-trained models like Word2Vec, GloVe, SBERT or the USE/GOOG (Google Universal Sentence Encoder); these models are trained to predict future text sequences on large amounts of unstructured text and can generate high-quality semantically rich embeddings. Once we have embeddings for each summary (machine and human), we compute the distance between them using a distance metric like cosine similarity. Similar to the Levenshtein distance algorithm, the lower the distance, the more similar the summaries are.
The advantage of using embeddings over string-based comparison methods is that they can capture more nuanced similarities between text, such as synonyms or related concepts, and are less sensitive to differences in phrasing or word order. However, they may still have limitations in cases where the meaning of a summary is drastically different from that of the original text, or where the embeddings have not been trained on domain-specific vocabulary.
Comparing Metrics

To compare the effectiveness of different metrics in determining semantic similarity, we run a set of prompts not included in our dataset through our model and analyze the results. We then compare these summaries using several metrics, including SBERT, USE, BertScore, and WMS. We found that wms/sms/s+wms did not generate intuitive match strengths as evidenced by the discrepancies in score listed in the graphic above (See the prompt “Florence is a beautiful city.” above), while BS-F1, SBERT, USE/GOOG outperformed the other metrics in determining semantic similarity and accurately matched the hypothesis string.
Compared to string-based comparison methods, embeddings have the benefit of being able to identify more complex similarities between text. This includes recognizing synonyms or related concepts that may not be immediately obvious from the text alone. Additionally, embeddings are not as adversely impacted by differences in how words are arranged or the specific phrasing used in the text. However, when it comes to assessing string similarity, it's important to utilize both a string-based and embedding approach.

Need help answering the following questions?
Talk it over with our AI bot Xybo.
Why do Metrics Matter?
After having assessed the previous AI21 LLM model through these metrics, we construct a custom summarization model to further improve the accuracy of our LLM. By analyzing the generated summaries through metrics targeting different subjects, we are able to identify areas where our LLM falls short and make targeted improvements. This approach allowes us to fine-tune our LLM to better match human performance and provide more accurate summaries.
To improve the overall effectiveness of Large Language Models (LLMs), it is crucial to evaluate their performance using reliable metrics, evolve the training data, and optimize parameters like temperature for specific tasks. Reliable metrics help us identify areas where our LLM may be lacking; continuously incorporating new data and optimizing model parameters helps us improve the model. The effectiveness of LLMs depends highly on the quality and diversity of training data and the parameters set for specific tasks. Therefore, we need to constantly monitor and improve both the data and parameters to ensure that our LLMs are performing at their best.
Consistently evaluating and adjusting LLMs allows them to learn more effectively and improve performance over time. By optimizing parameters such as temperature, we fine-tune the LLM for specific tasks, like summarization or scriptwriting; this fine tuning improves model effectiveness. While reliable evaluation metrics are crucial for assessing LLM performance, they are just one part of the overall process of improving and optimizing these models.
In the field of natural language processing, the LLM performance is typically evaluated using a variety of metrics. These metrics help to assess the ability of a model to perform various tasks, such as text classification, language translation, and text similarity. Reliable comparison metrics are crucial for accurately assessing the performance and growth of LLMs over time. One commonly used metric for evaluating the performance of LLMs in text similarity tasks is ROUGE. While ROUGE has its benefits, it is insufficient for capturing more complex similarities between texts, such as recognizing synonyms or related concepts that may not be immediately obvious from the text alone. This limitation can be particularly problematic in tasks where semantic similarity is crucial.
To overcome this limitation, we experimented with six commonly used metrics, including WMS, SMS, S+WMS, SBERT, BS-F1, and USE/GOOG, to identify the most reliable metrics for measuring semantic similarity between sentences.
Our results show that sentence embeddings, such as those used in SBERT, BS-F1, and USE/GOOG, consistently outperform the other metrics.
Compared to word-based methods, sentence embeddings have the advantage of being able to capture the underlying meaning and context of sentences, making them more effective for measuring semantic similarity.
These findings suggest that researchers and practitioners may be able to use SBERT, BS-F1, and USE/GOOG with confidence when evaluating the efficacy of LLMs, particularly in the application of generative tasks like summarization where machine/human comparisons are appropriate.
Conclusion
The effectiveness of Large Language Models is highly dependent on the quality and diversity of training data, as well as the parameters set for specific tasks. While reliable evaluation metrics like SBERT, BS-F1, and USE/GOOG are crucial for assessing the performance of LLMs, they are just one part of the overall process of improving and optimizing these models. By regularly evaluating and comparing the results of different metrics, and by evolving the training and test data for a given task, we can identify areas where our LLM may be lacking and take steps to improve. For example, we might direct humans toward areas of machine/human disagreement to refine and extend training data. Ultimately, this ongoing process of evaluation and improvement is essential for ensuring that LLMs continue to advance and deliver more accurate and effective results.
SOURCES:
Shankar, G. (2022, March 20). CNN-DailyMail News Text Summarization. Kaggle. https://www.kaggle.com/datasets/gowrishankarp/newspaper-text-summarization-cnn-dailymail
Cloudera. (2020). Few-Shot Text Classification. Fast Forward Labs. https://few-shot-text-classification.fastforwardlabs.com/#:~:text=Few%2Dshot%20learning%20for%20classification,categories%20both%20quickly%20and%20effectively
Acuna, D. (2022, December 13). Paraphrase Identification with Deep Learning: A Review of Datasets and Methods. Cornell University. https://arxiv.org/abs/2212.06933
Donal et al. (2023, March 6). Paraphrase Identification (State of the art). The Association for Computational Linguistics. https://aclweb.org/aclwiki/Main_Page
Pennington, J., Soccer, R., Manning., C. (2014). GloVe: Global Vectors for Word Representation. Stanford. https://nlp.stanford.edu/projects/glove/
SBERT. (2022). SentenceTransformers Documentation. SBERT. https://www.sbert.net/
Mensio, M. (2022, July 11). Spacy - Universal Sentence Encoder. Github. https://github.com/MartinoMensio/spacy-universal-sentence-encoder
Ajanki, A. (2020, July 28). Sentence embedding models. Antti Ajanki. https://aajanki.github.io/fi-sentence-embeddings-eval/index.html